Publications
Publications in reversed chronological order.
2023
-
 Cackle: Analytical Workload Cost and Performance Stability With Elastic PoolsMatthew Perron, Michael Cafarella, Raul Castro Fernandez, David DeWitt, and Samuel MaddenProc. ACM Manag. Data, Dec 2023
Cackle: Analytical Workload Cost and Performance Stability With Elastic PoolsMatthew Perron, Michael Cafarella, Raul Castro Fernandez, David DeWitt, and Samuel MaddenProc. ACM Manag. Data, Dec 2023Analytical query workloads are prone to rapid fluctuations in resource demands. These rapid, hard to predict resource demand changes make provisioning a challenge. Users must either over provision at excessive cost or suffer poor query latency when demand spikes. Prior work shows the viability of using cloud functions to match the supply of compute to the workload demand without provisioning resources ahead of time. For low query volumes, this approach is less costly at reasonable performance compared to provisioned systems, but as query volumes increase the cost overhead of cloud functions outweighs the benefit gained by rapid elasticity. In this work, we propose a novel strategy combining rapidly scalable but expensive resources with slow to start but inexpensive virtual machines to gain the benefit of elasticity without losing out on the cost savings of provisioned resources. We demonstrate a technique that minimizes cost over a wide range of workloads, environmental conditions, and compute costs while providing stable query performance. We implement these ideas in Cackle and demonstrate that it achieves similar performance and cost per query across a wide range of workloads, avoiding the cost and performance cliffs of alternative approaches.
-
 Selecting between hydration-based scanning and stateless scale-out scanning to improve query performanceIppokratis Pandis, and Matthew PerronJun 2023US Patent App. 18/171,245
Selecting between hydration-based scanning and stateless scale-out scanning to improve query performanceIppokratis Pandis, and Matthew PerronJun 2023US Patent App. 18/171,245


2020
-
 Starling: A Scalable Query Engine on Cloud FunctionsMatthew Perron, Raul Castro Fernandez, David DeWitt, and Samuel MaddenIn Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Jun 2020
Starling: A Scalable Query Engine on Cloud FunctionsMatthew Perron, Raul Castro Fernandez, David DeWitt, and Samuel MaddenIn Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Jun 2020Much like on-premises systems, the natural choice for running database analytics workloads in the cloud is to provision a cluster of nodes to run a database instance. However, analytics workloads are often bursty or low volume, leaving clusters idle much of the time, meaning customers pay for compute resources even when underutilized. The ability of cloud function services, such as AWS Lambda or Azure Functions, to run small, fine granularity tasks make them appear to be a natural choice for query processing in such settings. But implementing an analytics system on cloud functions comes with its own set of challenges. These include managing hundreds of tiny stateless resource-constrained workers, handling stragglers, and shuffling data through opaque cloud services. In this paper we present Starling, a query execution engine built on cloud function services that employs a number of techniques to mitigate these challenges, providing interactive query latency at a lower total cost than provisioned systems with low-to-moderate utilization. In particular, on a 1TB TPC-H dataset in cloud storage, Starling is less expensive than the best provisioned systems for workloads when queries arrive 1 minute apart or more. Starling also has lower latency than competing systems reading from cloud object stores and can scale to larger datasets.

2019
-
 Choosing a cloud DBMS: architectures and tradeoffsJunjay Tan, Thanaa Ghanem, Matthew Perron, Xiangyao Yu, Michael Stonebraker, David DeWitt, Marco Serafini, Ashraf Aboulnaga, and Tim KraskaProceedings of the VLDB Endowment, Jun 2019
Choosing a cloud DBMS: architectures and tradeoffsJunjay Tan, Thanaa Ghanem, Matthew Perron, Xiangyao Yu, Michael Stonebraker, David DeWitt, Marco Serafini, Ashraf Aboulnaga, and Tim KraskaProceedings of the VLDB Endowment, Jun 2019As analytic (OLAP) applications move to the cloud, DBMSs have shifted from employing a pure shared-nothing design with locally attached storage to a hybrid design that combines the use of shared-storage (e.g., AWS S3) with the use of shared-nothing query execution mechanisms. This paper sheds light on the resulting tradeoffs, which have not been properly identified in previous work. To this end, it evaluates the TPC-H benchmark across a variety of DBMS offerings running in a cloud environment (AWS) on fast 10Gb+ networks, specifically database-as-a-service offerings (Redshift, Athena), query engines (Presto, Hive), and a traditional cloud agnostic OLAP database (Vertica). While these comparisons cannot be apples-to-apples in all cases due to cloud configuration restrictions, we nonetheless identify patterns and design choices that are advantageous. These include prioritizing low-cost object stores like S3 for data storage, using system agnostic yet still performant columnar formats like ORC that allow easy switching to other systems for different workloads, and making features that benefit subsequent runs like query precompilation and caching remote data to faster storage optional rather than required because they disadvantage ad hoc queries.
-
 How I learned to stop worrying and love re-optimizationMatthew Perron, Zeyuan Shang, Tim Kraska, and Michael StonebrakerIn 2019 IEEE 35th International Conference on Data Engineering (ICDE), Jun 2019
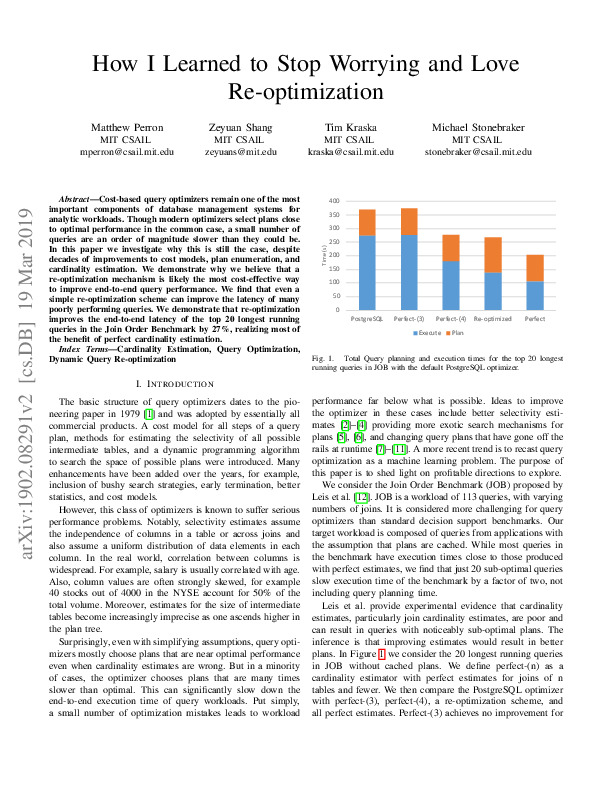
How I learned to stop worrying and love re-optimizationMatthew Perron, Zeyuan Shang, Tim Kraska, and Michael StonebrakerIn 2019 IEEE 35th International Conference on Data Engineering (ICDE), Jun 2019Cost-based query optimizers remain one of the most important components of database management systems for analytic workloads. Though modern optimizers select plans close to optimal performance in the common case, a small number of queries are an order of magnitude slower than they could be. In this paper we investigate why this is still the case, despite decades of improvements to cost models, plan enumeration, and cardinality estimation. We demonstrate why we believe that a re-optimization mechanism is likely the most cost-effective way to improve end-to-end query performance. We find that even a simple re-optimization scheme can improve the latency of many poorly performing queries. We demonstrate that re-optimization improves the end-to-end latency of the top 20 longest running queries in the Join Order Benchmark by 27%, realizing most of the benefit of perfect cardinality estimation.


2017
-
 Self-Driving Database Management Systems.Andrew Pavlo, Gustavo Angulo, Joy Arulraj, Haibin Lin, Jiexi Lin, Lin Ma, Prashanth Menon, Todd C Mowry, Matthew Perron, and 2 more authorsIn CIDR, Jun 2017
Self-Driving Database Management Systems.Andrew Pavlo, Gustavo Angulo, Joy Arulraj, Haibin Lin, Jiexi Lin, Lin Ma, Prashanth Menon, Todd C Mowry, Matthew Perron, and 2 more authorsIn CIDR, Jun 2017In the last two decades, both researchers and vendors have built advisory tools to assist database administrators (DBAs) in various aspects of system tuning and physical design. Most of this previous work, however, is incomplete because they still require humans to make the final decisions about any changes to the database and are reactionary measures that fix problems after they occur. What is needed for a truly “self-driving” database management system (DBMS) is a new architecture that is designed for autonomous operation. This is different than earlier attempts because all aspects of the system are controlled by an integrated planning component that not only optimizes the system for the current workload, but also predicts future workload trends so that the system can prepare itself accordingly. With this, the DBMS can support all of the previous tuning techniques without requiring a human to determine the right way and proper time to deploy them. It also enables new optimizations that are important for modern high-performance DBMSs, but which are not possible today because the complexity of managing these systems has surpassed the abilities of human experts. This paper presents the architecture of Peloton, the first self-driving DBMS. Peloton’s autonomic capabilities are now possible due to algorithmic advancements in deep learning, as well as improvements in hardware and adaptive database architectures.

2016
-
 Write-behind loggingJoy Arulraj, Matthew Perron, and Andrew PavloProceedings of the VLDB Endowment, Jun 2016
Write-behind loggingJoy Arulraj, Matthew Perron, and Andrew PavloProceedings of the VLDB Endowment, Jun 2016The design of the logging and recovery components of database management systems (DBMSs) has always been influenced by the difference in the performance characteristics of volatile (DRAM) and non-volatile storage devices (HDD/SSDs). The key assumption has been that non-volatile storage is much slower than DRAM and only supports block-oriented read/writes. But the arrival of new non-volatile memory (NVM) storage that is almost as fast as DRAM with fine-grained read/writes invalidates these previous design choices. This paper explores the changes that are required in a DBMS to leverage the unique properties of NVM in systems that still include volatile DRAM. We make the case for a new logging and recovery protocol, called write-behind logging, that enables a DBMS to recover nearly instantaneously from system failures. The key idea is that the DBMS logs what parts of the database have changed rather than how it was changed. Using this method, the DBMS flushes the changes to the database before recording them in the log. Our evaluation shows that this protocol improves a DBMS’s transactional throughput by 1.3×, reduces the recovery time by more than two orders of magnitude, and shrinks the storage footprint of the DBMS on NVM by 1.5×. We also demonstrate that our logging protocol is compatible with standard replication schemes.
